Feature Engineering
Model Variables:
The variable outcome is set as the target variable. The exploratory data analysis showed that form factor, FIFA ranks, Location of the game (country, continent), attack vs defense, dense vs attack, midfield and overall score have predictive power on the outcome of the game, we decided to include those in our model. Though the distribution of the average age among three outcome groups (win, draw, & lose) does not show any significant difference, we decided to include variable team average age with the assumption that average age might have some interaction effect with other predictors. In addition, we have included average population, distance between the team’s country. We have spent lot of effort on collecting team chemistry data, but we could find the team chemistry record only for 230 observations in our model data, so we decided to drop that variable from the model.
|
Model Variable |
Type |
Description |
|
Outcome |
Categorical |
Target variable with 3 classes (values: -1, 0 and 1). The -1 indicates that Team 1 is the winner, 0 indicates the game ended in draw, -1 indicates the Team 1 is the loser. |
|
Team1 |
Categorical |
Team names of team-1 |
|
Team1 |
Categorical |
Team names of team-2 |
|
Rank_diff: |
Ordinal |
Difference in FIFA rank between team-1 and team-2 |
|
RollingFormDiff: |
quantitative |
Difference in Form Factor between team-1 and team-2 |
|
distance_diff: |
Quantitative |
Difference in distance between team-1 country and team-2 country |
|
attack_diff: |
quantitative |
Difference in average attack score between team-1 and team-2 |
|
midfield_diff: |
quantitative |
Difference in average midfield score between team-1 and team-2 |
|
age_diff: |
quantitative |
Difference in team-1 average and team-2 average age |
|
overall_diff: |
quantitative |
Difference in average overall score of team-1 and team-2 |
|
game_location: |
Categorical |
Country where the game is conducted (values: home – game is conducted at team-1’s country, away – game is conducted at team-2’s country; neutral – game is conducted at common country. |
|
game_continent: |
Categorical |
Continent where the game is conducted (values: same – team-1 and team-2 are from same continent and the game is conducted in the same continent; home- game is conducted at team-1’s continent; away – game is conducted at team-2’s continent; neutral – game is conducted at common continent. |
|
pop_diff: |
Quantitative |
Difference in the population between team-1 country and team -2 country. |
|
diffence_diff: |
quantitative |
Difference in average defense score between team-1 and team-2. |
Dummy Variables: Dummy variables are created for the categorical features, and the original categorical features are dropped from the input data matrix. while creating a set of dummy variables for a categorical feature with n categories, we dropped one category and created n-1 dummy variables.
Missing Values: The features related to team strength have values only from 2007. We wanted to experiment the models with different options for handling missing values.
Feature Scaling: StandardScaler is used to transform the all features with mean zero and standard deviation of 1.
Polynomial Features: we wanted to experiment our model with adding more polynomial features and interaction terms.
midfield_diff,age_diff,overall_diff.
Interaction term 1 = [game_location_home, game_location_neutral]
Interaction term 2 = [Rank_diff, RollingFormDiff, diffence_diff, attack_diff, midfield_diff,
overall_diff]
Design Matrix:
Split x and y:
The variable Outcome is dropped from the input data matrix and considered as a target variable.
Split Train and Test:
The world cup 2018 matches are dropped from the input data matrix and considering as test data set. The remaining data are considered for model training the validation.
Split train and Validation:
20% of the random samples from the training data is removed for model cross validation and the remaining 80% of the data is used for model training.
We have built many models to predict the outcome of 2018 world cup games: 1. Logistics Regression (LR), 2. Linear Discriminant Analysis (LDA), 3. k-Nearest Neighborhood (kNN), 4. Decision Tree (CART), 5. Gaussian NB (NB), 6. Support Vector Machines (SVM), 7.Random Forest (RF), 8. Gradient Boosting Classifier (GB), 9. AdaBoost Classifier (AB) and 10. Multilayer Perceptron (MLP) Neural Network. We pick a few of them to explain the process.
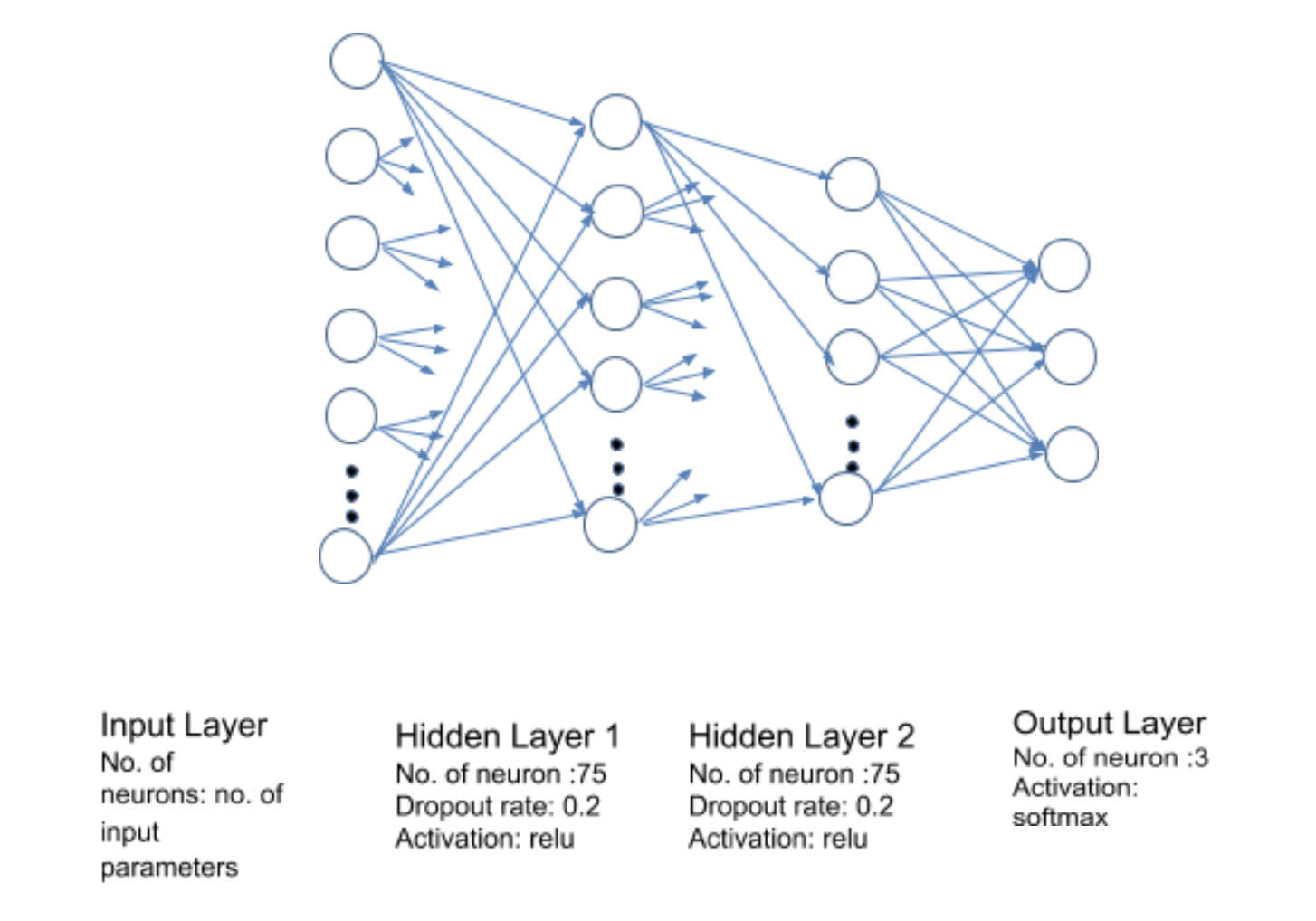
Optimizer = sgd with; learning rate = 0.9; decay rate = 0.02/num_epochs; batch_size = 512.
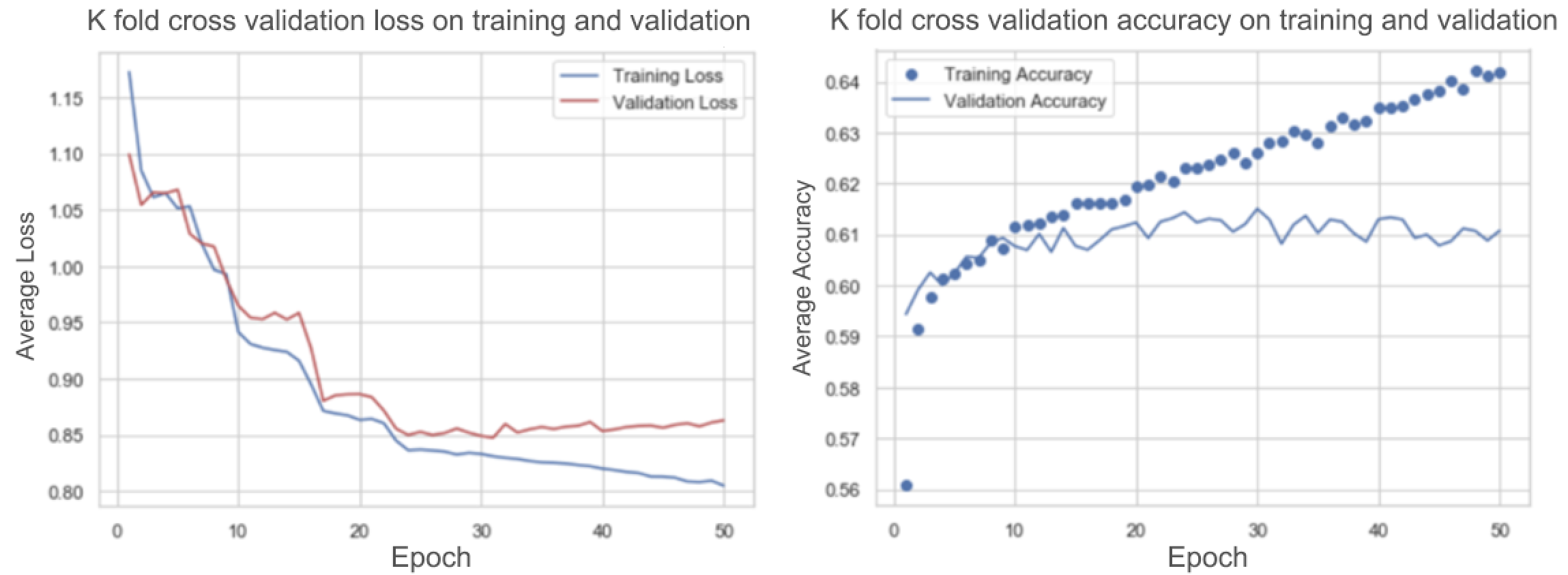
We experimented with different input data set generated using different missing value handling methods. The input data set where the missing values are imputed showed better performance than the input data with missing values removed one. K – fold cross validation is done with 4 folds and 50 number of epochs to identify the optimal number of epochs for the network. The cross validation mean accuracy and loss on training and valid data set shows that the model starts overfitting after 40 epochs.
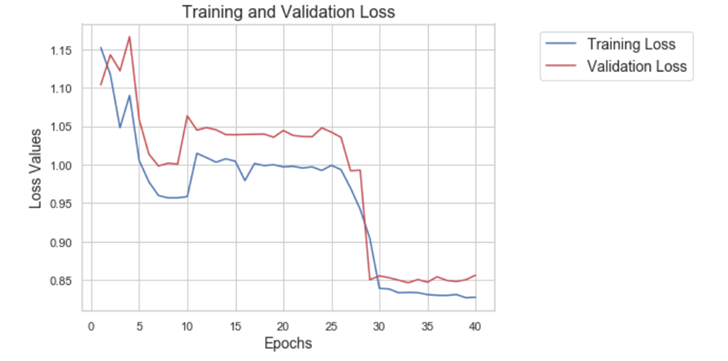
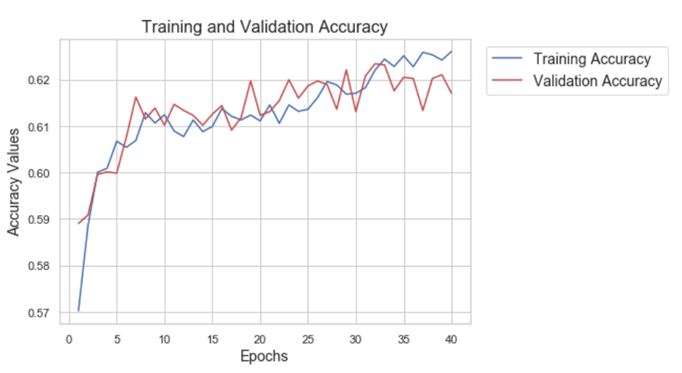
The model is re-trained using for 40 epochs, and the loss and accuracy score are monitored. The trained model is used to predict the game outcome on test data set. The model accuracy on validation set is 0.62 and on test data set is 0.51. This is somewhat of a disappointment and we guess it could be because the test set is quite different from the train set (like the example in HW9). The test set contains all the games played in Russia with many neutral games. We probably have to re-think how the training set needs to be considered. It is possible to take a smaller set where the test set is in good alignment with the train set (only World Cup matches?). However, given lack of time, we have not tried much in that direction and leave it for future work.
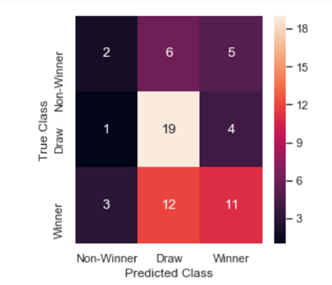
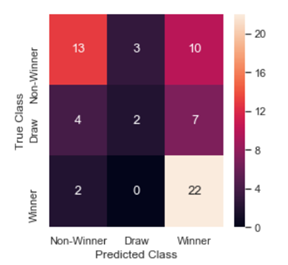
Confusion Matrix on Test data:
The support vector machine classifier is built with different kernels and regularization parameter. The model with rbf kernel and regularization parameter C=1 produced better cross validation accuracy score of 0.61. The trained model is used to predict the outcome of the 2018 world cup games (test data). The accuracy score on the test data is 0.59.
The confusion matrix shows that SVM classifier has high sensitivity to Winner class.
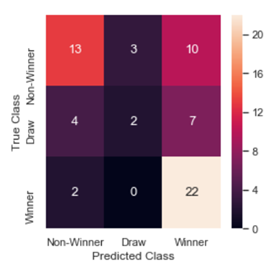
3. Ada Boosting Classifier:
The ada-boosting classifier is built and trained on the training data. We experimented with different parameter settings for number of estimator, learning rate and found that the default setting of n_estimators = 50 and learning rate learning_rate =1 and SAMME.R ada-boosting algorithm produced better cross validation accuracy of 0.61. The trained ada boost model is used to predict the outcome on the test data. The accuracy score on the test data is 0.59.
The confusion matrix for test data shows that Ada boosting classifier has high sensitivity to Winner class.
Comparison of Model Performance
|
Model |
Running Time on training data |
Cross Validation Accuracy |
Test Accuracy |
F1-score (test data) |
Precision on Winner Class (test data) |
Recall on Winner Class (test data) |
|
Neural Network |
11.559 seconds |
0.62 |
0.51 |
0.48 |
0.55 |
0.42 |
|
Support Vector Machine (SVM) |
1143.62 seconds |
0.61 |
0.59 |
0.70 |
0.56 |
0.92 |
|
Ada Boosting |
6.102 seconds |
0.61 |
0.59 |
0.70 |
0.56 |
0.92 |
|
|
|
|
|
|
|
|
Comparing all the above four models shows that neural network does not give better accuracy score on test data though it has higher accuracy score on cross validation set. SVM and Ada Boosting give same accuracy score on cross validation and test data. It shows that neural network overfitted to training data though we have introduced drop outs and regularization parameters. In terms of running time, the SVM is very slow and computationally very expensive. Ada boosting is built on week learners, and it converges very quickly.
Comparative Study on Different Classifiers
We wanted to experiment with the different classifiers to understand how different classifiers perform on world cup data.
Models considered in the analysis:
1. Logistic Regression – liblinear solver
2. Linear Discriminant Analysis
3. K-Nearest Neighborhood Classifier
4. Decision Tree Classifier - loss function gini score
5. Naïve Bayes Classifier
6. Support Vector Machine Classifier - loss function squared_hinge
7. Random Forest Classifier – loss function gini score
8. Gradient Boosting Classifier - loss function MSE
9. Ada Boost Classifier
We used the default parameter setup in sklearn for all the models in order to have the fair comparison of the models.
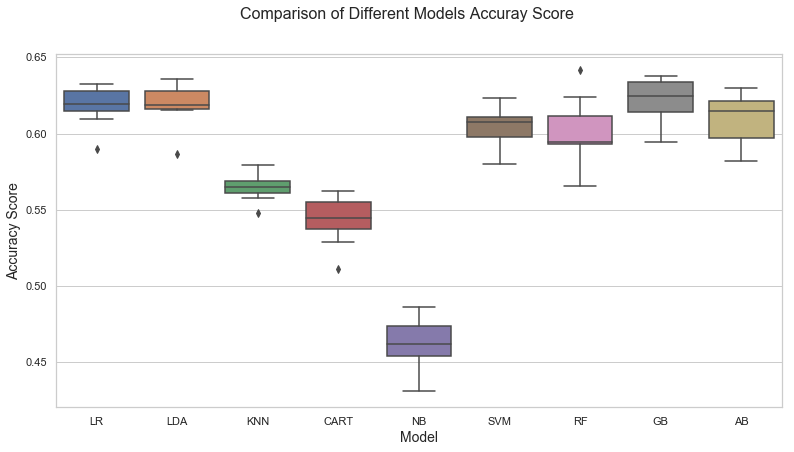
Ten-fold cross validation is used to measure the consistency of the performance metrics. The accuracy score is used as a measure of performance. The box plots show the median accuracy score and the spread of the accuracy scores. The top winning models are logistic regression, linear discriminant analysis, gradient boosting classifier and Ada boost classifier. The top performance models have mean accuracy score around .63. The SVM and Random Forest models are closer to top performing models. The Naïve Bayes classifier is the worst model which has the median accuracy score around .46 which is very low compared to top performing models. The results of the decision tree is a surprise to us, the accuracy score of decision tree is lower than the KNN model. It shows that the decision tree might have difficulty to find a best split with too many categories in team 1 and team 2 feature and have overfitting issue. Boosting models (Gradient Boosting and Ada Boosting) are robust to overfitting and shows good performance score.
Performance Metrics Comparison
The performance of all 9 models are tested on the test data set. The test data set accuracy shows that the ada boosting has top accuracy score of 0.62
|
Model |
Test Accuracy |
|
Logistic Regression |
0.58 |
|
Linear Discriminant Analysis |
0.60 |
|
K-Nearest Neighborhood Classifier |
0.51 |
|
Decision Tree Classifier |
0.54 |
|
Naïve Bayes Classifier |
0.30 |
|
Support Vector Machine Classifier |
0.59 |
|
Random Forest Classifier |
0.49 |
|
Gradient Boosting Classifier |
0.52 |
|
Ada Boosting Classifier |
0.62 |
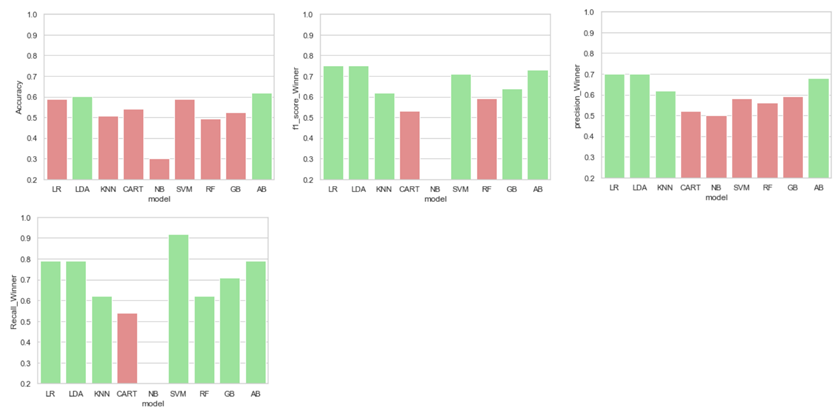
Models Performance on predicting the Winner class:
The accuracy plot on winner class shows that the Ada boosting and Linear Discriminant Analysis performs well on predicting the winner class. The overall metrics f1-score shows that the overall performance of Decision Tree and Naïve Bayes models are low on predicting the winner class. The high recall score of the SVM shows high sensitivity on predicting the winner class.
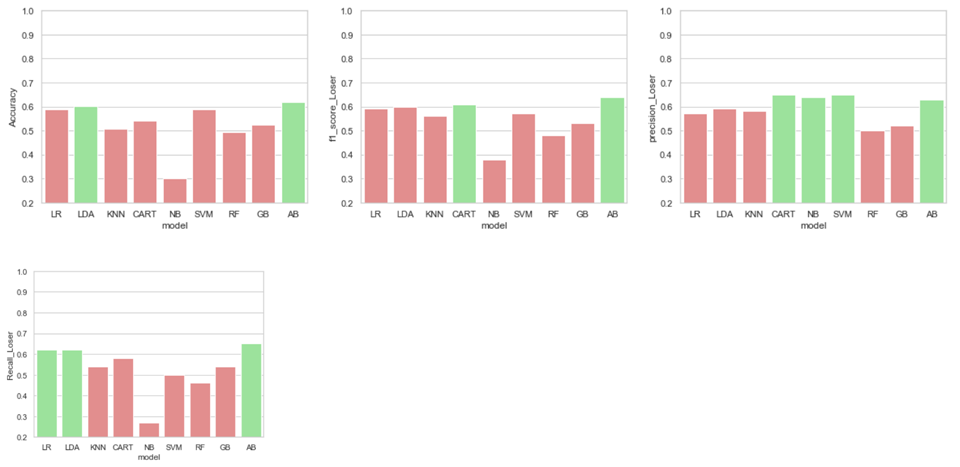
Models Performance on predicting the Loser class:
The accuracy plot on loser class shows that the Ada boosting and Linear Discriminant Analysis performs well on predicting the loser class. The overall metrics f1-score shows that Decision Tree and Ada boosting have high performance on predicting the loser class. The high recall score of the Ada boosting shows high sensitivity on predicting the loser class.
Based on our comparative analysis, we conclude that Boosting Models: Ada boosting, Gradient Boosting, SVM, Logistic regression and Random Forest Models can be used to model the world cup game prediction problem.
Fine-tuning of Random Forest Model (Best Model)
From the charts, we can see several models hitting about 60-65% accuracy. Given more time, we could try tuning the models further. However, when the Random Forest model was tuned, we were able to achieve a score of 66.67% on the test set (when including draws), which seems to be our best score achieved. This was achieved by limiting the number of trees to 500 and stopping at a maximum depth of 9. If we spend more time on the other models and tune them further, they might achieve this accuracy or even better but for the sake of this project our best model is Random Forest with 66.67% accuracy on the test set.
Accuracy of Final Random Forest model on train set: 67.52 %
Accuracy of Final Random Forest model on test set: 66.67 %